웹에서 미국 ETF 리스트 가져오기 - Requests/ bs4 (BeautifulSoup)
야후, 구글이 Finance API를 변경함에 따라, 미국 주식의 가격정보를 파이썬(Python)으로 가져올 수 없게 되었습니다. Morningstar를 비롯한 몇 개 사이트에서는 여전히 API를 열어 두고는 있는데요.
Morningstar에서 가격 정보를 가져오기 전에, 미국 ETF 리스트를 먼저 구해 보겠습니다. 위키피디아에서 미국 ETF 리스트 정보(https://en.wikipedia.org/wiki/List_of_American_exchange-traded_funds) 를 제공하고 있습니다.
오늘 필요한 Python 라이브러리는 requests와 bs4 (BeautifulSoup)입니다. 아나콘다(Anaconda)를 설치한 경우 별도로 라이브러리를 설치할 필요가 없습니다. 아니라면, 별도로 install 하여 설치해 주어야 합니다. 먼저 requests로 url에서 필요한 html을 가져옵니다.
Requests로 html 가져오기
url에 위키피디아 주소를 저장하고, request로 페이지에 가서 응답 결과를 resp라는 변수에 할당합니다.
|
# requests 라이브러리 불러 오기 import requests # requests로 url에서 데이터 가져오기 url = 'https://en.wikipedia.org/wiki/List_of_American_exchange-traded_funds' resp = requests.get(url) soup = bs.BeautifulSoup(resp.text, 'lxml') |
resp를 출력해 보면, 의미를 해석할 수 없는 객체입니다. 200이라는 숫자는 http 호출이 정상적이라는 뜻입니다.

우리가 이해할 수 있는 소스코드를 얻기 위해서는 .text 구문을 이용하여 html 소스를 불러와야 합니다. resp 객체에 .text구문을 결합하여 resp.text로 입력하면 html 소스코드를 가져옵니다.

이 단계까지 하고 나면, BeautifulSoup을 활용할 때가 되었습니다.
BeautifulSoup으로 Parsing 하기
soup = bs.BeautifulSoup(resp.text, 'lxml')과 같이 resp.text 소스를 'lxml' 방식으로 해석한 내용을 soup에 저장하라는 뜻입니다. 여기서 'lxml'을 Parser라고 하는데, 따로 지정해주지 않으면 default 값으로 'html.parser'가 적용됩니다. 'lxml'의 처리 속도가 더 빠르다고 합니다.
|
rows = soup.select('div > ul > li') |
BeautifulSoup으로 파싱 한 결과를 soup 객체에 담고 있는데, BeautifulSoup의 select를 사용하여 필요한 정보만 선택할 수 있습니다. 먼저 soup 객체가 어떻게 생겼는지 보겠습니다. html 구조를 확인할 수 있습니다.
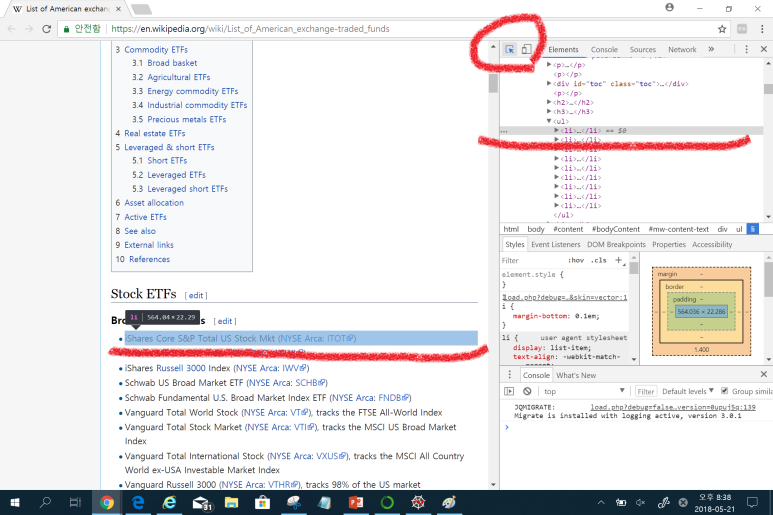
구글 크롬 개발자 도구로 우리가 찾는 정보가 위치한 CSS Selector를 먼저 복사합니다. 크롬 화면에서 Ctrl + Shift + I 를 누르면 개발자 도구가 활성화됩니다. 오른쪽 상단의 화살표를 마우스로 클릭하고, 왼쪽 ETF 제목 위에 커서를 갖다 대면 회색 음영으로 영역이 나타납니다. 마우스 좌 클릭으로 영역을 선택하면 오는 쪽 작은 윈도에 우리가 찾는 부분이 선택된 것을 확인할 수 있습니다.
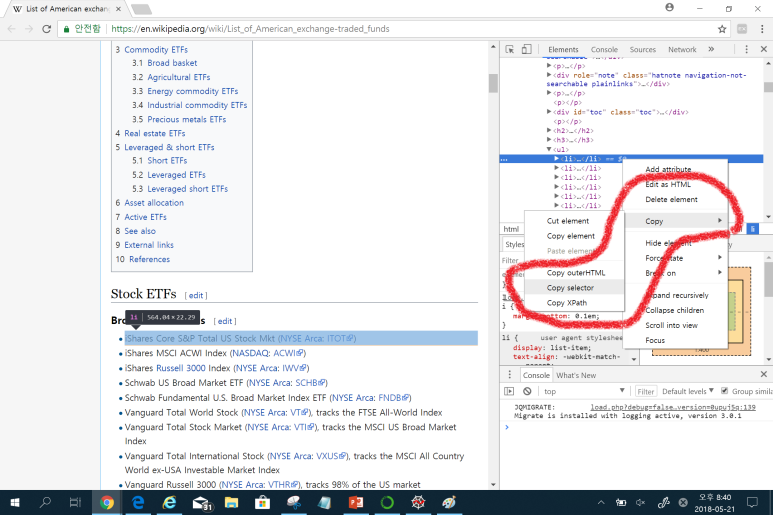
오른쪽 CSS 구분에 선택된 부분에서 마우스 우 클릭을 하면, CSS selector를 Copy할 수 있는 팝업메뉴가 나타납니다. Copy selector를 선택해서 editor에 붙여넣기하면 '#mw-content-text > div > ul:nth-child(10) > li:nth-child(1)'으로 표시됩니다. 이대로 선택해도 되지만, 우리는 다른 ETF에 대해서도 한꺼번에 불러오기를 원하기 때문에, 'div > ul > li' 과 같이 빨간색으로 표시한 CSS 주요 요소만 남겨 두고 나머지는 삭제합니다.
rows = soup.select('div > ul > li') 를 실행하여 soup 객체의 리스트가 반환되면 rows라는 변수에 저장합니다. rows를 출력하면, 여러 개의 etf 정보가 나타납니다. 자세히 살펴보면 etf 이름, 관련 link, ticker 등 필요한 정보가 들어 있습니다.

for 반복문을 실행하여, rows 리스트에 들어 있는 각각의 ETF 코드에 대하여, 우리가 필요한 etf 이름, 관련 link, ticker(거래소 종목코드)를 추출할 수 있습니다.
|
for row in rows: etf_name = row.text etf_link = row.find('a').get('href') etf_ticker = row.find('a', {'class': 'external text', 'rel' : 'nofollow'}).text |
etf 이름은 row를 구성하는 가장 큰 요소인 <li> 태그의 text이므로 .text구문으로 가져옵니다. etf 링크는 row에서 첫 번째 <a> 태그 안의 href 속성입니다. row.find('a').get('href')로 찾을 수 있습니다. 마지막으로 ticker는 <a> 태그 중에서 class="external text", rel="nofollow" 속성을 갖는 태그의 text 값입니다. BeautifulSoup의 find 구문을 활용하여 가져옵니다.
위와 같은 방법으로 soup 개체 리스트에서 필요한 속성을 찾아서 원하는 정보를 추출한 다음에, ETF의 ticker를 key 값으로 하는 dictionary 형태로 저장합니다.
|
etfs = { } if len(etf_ticker) > 4: pass else: etfs[etf_ticker] = [etf_name, etf_link] |
이때 주의할 사항은 etf_ticker 자리에 다른 정보가 들어 있는 row 값들이 있다는 건데요. 미국 주식시장의 ticker는 4자리가 최대이므로, etf_ticker의 문자열이 4보다 크다면 dictionary에 포함하지 않으면 됩니다. ETF의 개수는 389개이고, 정리된 ETF 목록이 아래와 같이 정리된 것을 확인할 수 있습니다.

다음에는 이번에 정리한 ETF 목록을 가지고, Morningstar API를 활용하여 각각 ETF의 price history를 불러오는 작업을 해볼까 합니다.