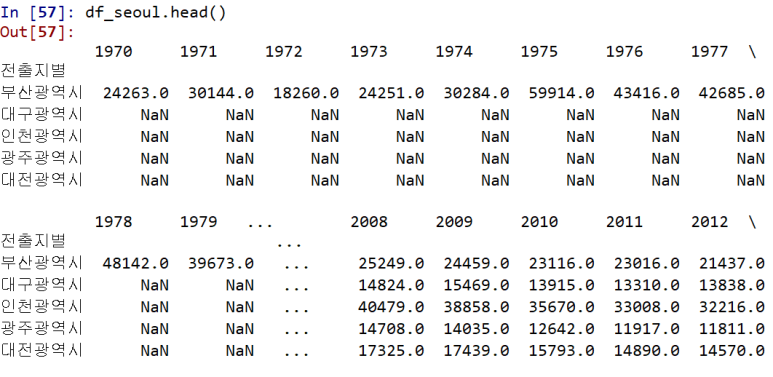
파이썬 Pandas 데이터 클렌징 (Data Cleansing)
파이썬 Pandas 데이터 클렌징 (Data Cleansing)

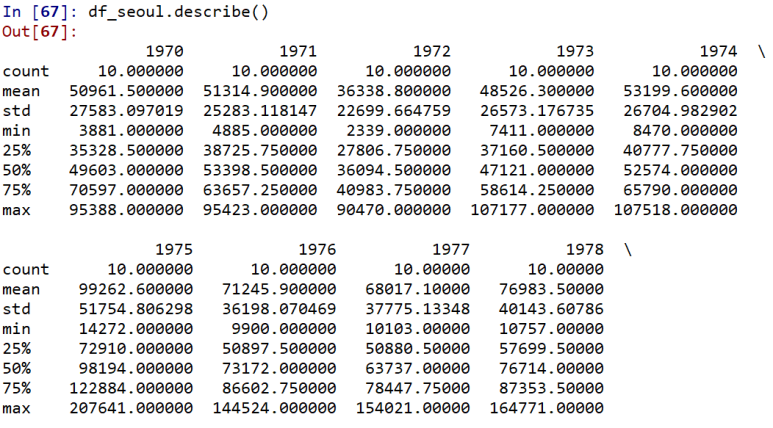
파이썬 Pandas 열(column) 평균값(mean)
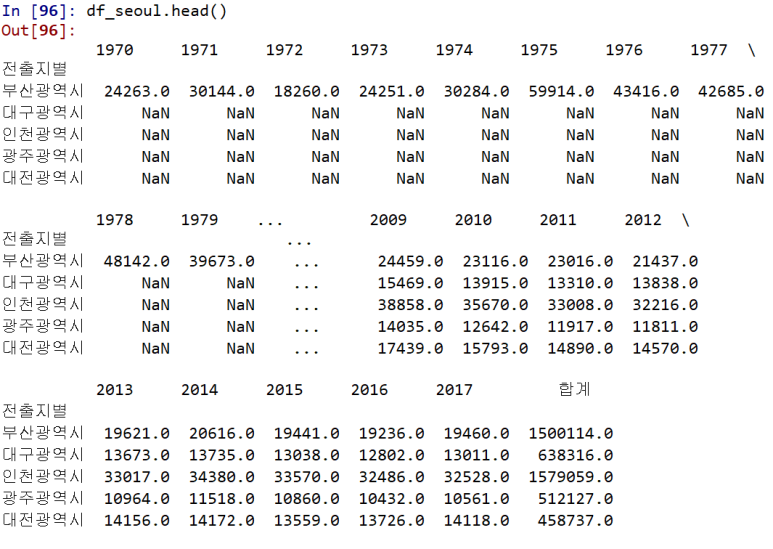
파이썬 pandas 열(column) 합계
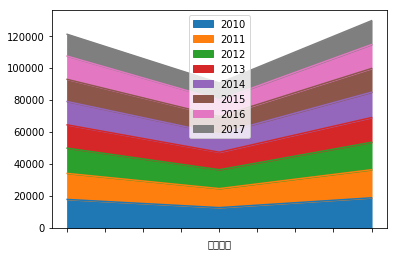
파이썬 matplotlib.pyplot - Area Plot
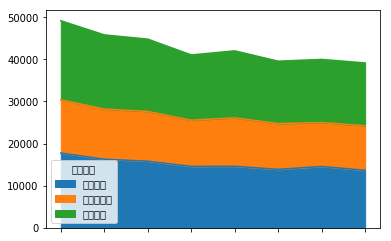
파이썬 matplotlib.pyplot - Area Plot
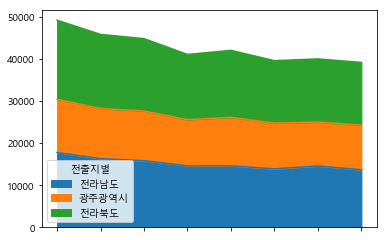
파이썬 matplotlib.pyplot - Area Plot
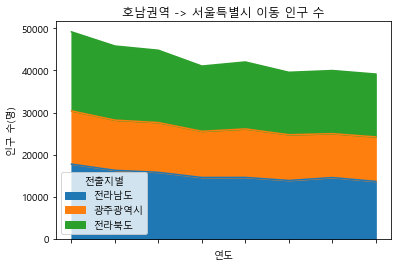
파이썬 matplotlib.pyplot - Area Plot